图的邻接表定义
下面用邻接表实现图的深度优先搜索和广度优先搜索,用邻接矩阵来实现最小生成树。
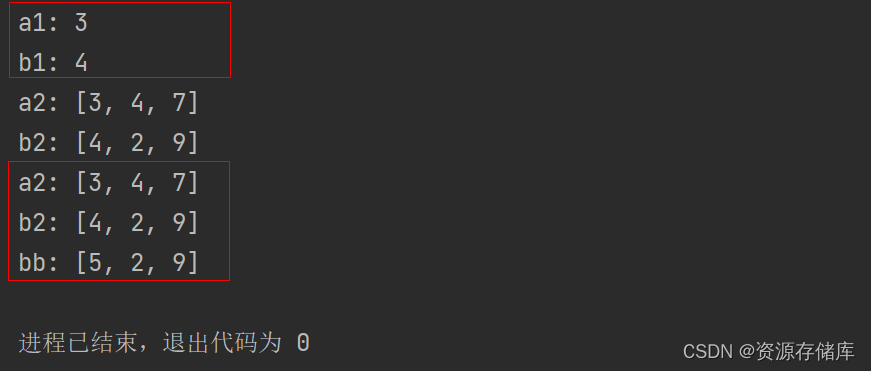
图的邻接表:首先定义一个图的邻接表的类,里面包括图的顶点数,图的边数,顶点表数组。由于顶点表数组里存放的都是图的一个个节点,因此需要用到顶点节点和边的节点。定义顶点节点的结构体中数据域中存放顶点的信息,指针域指向边表的第一个节点,用first来表示。定义边节点的数据域中存放被指向的节点的信息,指针域指向下一个边表节点,用next表示。
图的邻接表的类的成员函数包括图的构造函数,深度优先搜索,广度优先搜索。下面给出图的邻接表的类的定义以及顶点节点和边节点的定义。
#define Maxvernum 20
#define inf 0x3f3f3f3f
//边表(节点)
template<typename datatype>
struct arcnode
{
int adjvex;//所指向的顶点是哪个(用两个节点在逻辑上连接了一条弧)
arcnode<datatype>* next; //指向此边表的下一个节点(同样也是用两个节点在逻辑上连接了一条弧)
};
//顶点表(节点,边表的特殊情况)
template<typename datatype>
struct vertexNode
{
datatype data;//顶点信息
arcnode<datatype>* first;//指向的第一个节点
};
//图类(用邻接表的方式存储图)
template<typename datatype>
class graph
{
public:
graph();//图的构造函数
void bfs(datatype);//广度优先搜索
void dfs(datatype);//深度优先搜索
private:
int vernum;//顶点数
int arcnum;//边数
vertexNode<datatype> adj_list[Maxvernum];//顶点表
};图的邻接表构造函数
首先先输入邻接表的顶点数和边数,接下来输入每个顶点的值,将其存放在顶点表中每个顶点元素的数据域当中,将当前顶点表的每个节点的first都设为空。接下来按照边的数目,依次输入哪两个节点之间存在边,并在邻接表中将他们互相连接到各自的边表中,比如A和B相连,就让A的边表节点中有B,B的边表节点中有A,按照这个方法依次构建,就构建出了图的邻接表。
广度优先搜索
广度优先搜索类似于树中按层序遍历,一层层进行遍历,得到广度优先遍历序列。在实现的时候用到了队列这种数据结构。为了避免重复搜索的情况出现,因此要设置一个标记数组,用于标记已经被搜索过的节点。首先先选取一个要从其开始进行搜索的节点,将其放入队列并标记,接下来依次遍历它的边表节点,只要没被标记,就将其入队,直到这个节点的边表节点被全部搜索完毕,输出这个顶点的值,并将其出队,下次取队头元素,继续按照上面的步骤进行搜索队头节点的边表节点,依次类推,直到队列为空,则说明广度优先遍历完成。代码如下
//广度优先搜索
template<typename datatype>
void graph<datatype>::bfs(datatype e)
{
queue<datatype> q;
int visited[Maxvernum] = { 0 };
q.push(e);//从编号为e的这个顶点开始
visited[e] = 1;
int s = e;
while (!q.empty())
{
s = q.front();//取队头元素
arcnode<datatype>* tmp = adj_list[s].first;
while (tmp!=NULL)
{
if (visited[tmp->adjvex] != 1)
{
q.push(tmp->adjvex);
visited[tmp->adjvex] = 1;
}
tmp = tmp->next;
}
cout << adj_list[q.front()].data << " ";
q.pop();
}
}深度优先搜索
深度优先遍历是使用递归的思想,这里我们采用栈这种数据结构来模拟递归的实现。深度优先搜索同样需要一个标记数组来标记已经被搜索过的节点,避免重复搜索。深搜是沿着一条路搜到底,直到没有节点可以继续往下搜,再逐层返回得到。首先先确定从某个节点开始进行深搜,并将这个节点进行标记,然后沿着这个节点的边表进行搜索,如果遇到没被搜索过的节点,就将其入栈,直到这个节点的边表被全部搜索完,接下来取栈顶元素,对其进行打印(这里注意与广搜不同,要先进行打印),然后再对这个元素继续上述的操作,以此类推,直到栈为空,则说明深度优先搜索已经完成,可以结束。代码如下
//深度优先搜索
template<typename datatype>
void graph<datatype>::dfs(datatype e)
{
stack<int> st;
int visited[Maxvernum] = { 0 };
st.push(e);
int s = e;
visited[e] = 1;
while (!st.empty())
{
s = st.top();
arcnode<datatype>* tmp = adj_list[s].first;
cout << adj_list[st.top()].data << " ";
st.pop();
while (tmp != NULL)
{
if (visited[tmp->adjvex] != 1)
{
st.push(tmp->adjvex);
visited[tmp->adjvex] = 1;
}
tmp = tmp->next;
}
}
}最小生成树
图的邻接矩阵定义
最小生成树用图的邻接矩阵的方式来编写,首先给出图的邻接矩阵的定义。其私有成员包括图的顶点数,边数,顶点数组,邻接矩阵的二维数组,成员函数包括构造函数,打印邻接矩阵的函数,生成最小生成树算法的函数。定义代码如下
//图类(用邻接矩阵的形式存储)
template<typename datatype>
class graph2
{
public:
graph2();//图(邻接矩阵)的构造函数
void show_matrix();//打印邻接矩阵
void prim();//prim最小生成树算法
private:
int vernum2;//顶点数
int arcnum2;//边数
datatype vertex[Maxvernum];//顶点数组
int graph_matrix[Maxvernum][Maxvernum];//图的邻接矩阵
};构造函数
根据顶点数建立相应大小的二维矩阵,然后把每个节点先设成inf(无穷大),然后根据输入确定哪两个节点之间有边,并确定它们之间的权值,然后将相应的位置的元素的数值设置为对应的权值,这里注意graph_matrix[i][j]和graph_matrix[j][i]都要设置相同的权值,因为两个节点连着的边是同一条边(因为是无向图,对应的邻接矩阵是一个对称矩阵)。代码如下
//图(邻接矩阵)的构造函数
template<typename datatype>
graph2<datatype>::graph2()
{
int weight = 0;
cout << "请输入顶点数和边数" << endl;
cin >> vernum2 >> arcnum2;
for (int i = 0; i < vernum2; i++)
{
for (int j = 0; j < vernum2; j++)
{
graph_matrix[i][j] = inf;
}
}
cout << "请输入各个顶点" << endl;
for (int i = 0; i < vernum2; i++)
{
cin >> vertex[i];
}
cout << "请输入哪两个点之间有边,以及这两个边的权值" << endl;
for (int i = 0; i < arcnum2; i++)
{
int m = 0, n = 0;
cin >> m >> n>>weight;
graph_matrix[m][n] = weight;
graph_matrix[n][m] = weight;
}
}打印邻接矩阵函数
代码如下
//打印邻接矩阵
template<typename datatype>
void graph2<datatype>::show_matrix()
{
for (int i = 0; i < vernum2; i++)
{
for (int j = 0; j < vernum2; j++)
{
cout << graph_matrix[i][j] << " ";
}
cout << endl;
}
}prim最小生成树算法
要生成最小生成树,采用不断将新的节点并入到最小生成树当中,直到没有节点被并入最小生成树了,那么就说明最小生成树已经完成了,因此还需要一个标记数组isjoined来判断节点是否被标记。首先先选取一个顶点作为最小生成树的起始点,首先要将这个点并入到最小生成树的集合当中。接下来需要寻找下一个能够被并入到最小生成树集合中的节点,每次选一个连接到当前最小生成树集合中花费最小的节点,因此需要一个lowcost数组来记录每个节点到最小生成树集合的花费,并且在每次最小生成树集合更新的时候,这些值如果想被更新,只可能比原来的花费更小,才会被更新。接下来在lowcost数组中寻找花费最小的节点,并将其并入到最小生成树集合中,并将这个节点标记,并将其加入到最小花费之和sum中,依次类推,直到所有节点都被标记,那么说明此时的sum就是最小生成树的最小花费。代码如下
//prim最小生成树算法(输出最小生成树的权值之和)
template<typename datatype>
void graph2<datatype>::prim()
{
int sum = 0;//权值之和
int flag = 0;
int isjoined[Maxvernum] = {0};//标记数组,判断是否被并入最小生成树,先全置为1,表示都未被标记过
int lowcost[Maxvernum] = { 0 };//最低耗费的数组
for (int i = 0; i < Maxvernum; i++)
isjoined[i] = 1;
for (int i = 0; i < Maxvernum; i++)
lowcost[i] = inf;
int vertex = 0;
cin >> vertex;//从哪个顶点开始进行最小生成树
isjoined[vertex] = 0;//将这个点标记
for (int k = 0; k < vernum2; k++)
flag += isjoined[k];
while (flag)//一旦标记数组为0,则说明所有节点的最小生成树已经完成
{
for (int i = 0; i < vernum2; i++)//如果当前节点未被标记过,那么就判断每个未被标记的节点与上一次刚加入到
{ //已经连接好的最小生成树中的节点直接是否会存在更短的路径,如果存在
//就将其更新,如果比lowcost[i]大,那么就不更新
if (isjoined[i] == 1)
{
lowcost[i] = min(lowcost[i], graph_matrix[vertex][i]);
}
}
int minx = inf;
for (int i = 0; i < vernum2; i++)
{
if (lowcost[i] < minx && isjoined[i] == 1)//在未被标记过的节点中寻找权值最小的节点,并标记
{
vertex = i;
minx = lowcost[i];
}
}
isjoined[vertex] = 0;
sum += minx;//加上新找到的那个节点与已经标记过的集合中的最小消耗
int u = 0;
for (int k = 0; k < vernum2; k++)
{
u+=isjoined[k];
}
flag = u;//更改标记数组的总和
}
cout << sum << endl;
}