二叉树是一种非常重要的数据结构,在计算机科学中得到广泛的应用。二叉树是一种树形结构,其中每个节点最多有两个子节点,分别称为左子节点和右子节点。在这篇文章中,我们将探讨二叉树的广度优先遍历和深度优先遍历。
广度优先遍历
广度优先遍历是指按照层级顺序逐层遍历二叉树。从二叉树的根节点开始,逐层遍历每个节点。对于每一层,我们先遍历左子节点,再遍历右子节点。这种遍历方式通常使用队列来实现。
以下是一个二叉树的示例:
1
/ \
2 3
/ \ \
4 5 6
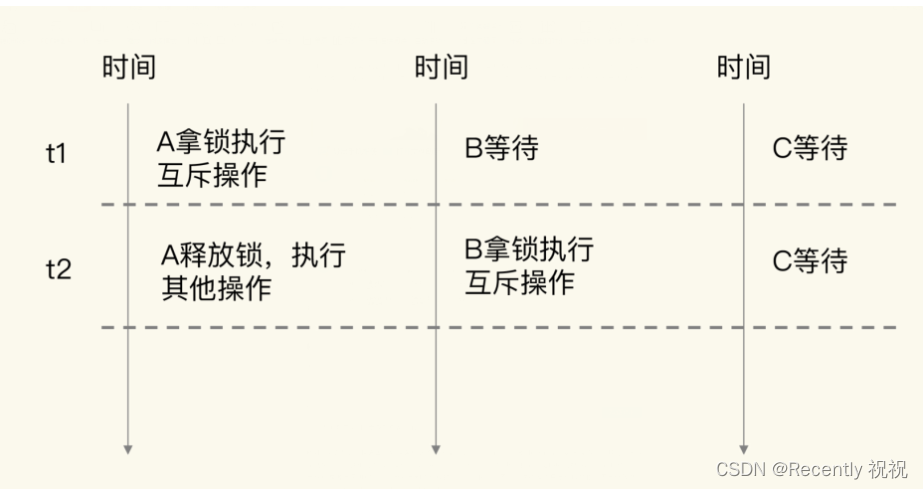
广度优先遍历的顺序为:1, 2, 3, 4, 5, 6。遍历过程如下:
- 将根节点1入队。
- 从队列中取出1并输出。
- 将1的左子节点2和右子节点3入队。
- 从队列中取出2并输出。
- 将2的左子节点4和右子节点5入队。
- 从队列中取出3并输出。
- 将3的右子节点6入队。
- 从队列中取出4并输出。
- 从队列中取出5并输出。
- 从队列中取出6并输出。
深度优先遍历
深度优先遍历是指以深度优先的方式遍历二叉树。从根节点开始,先遍历左子节点,然后遍历右子节点,直到遍历到叶子节点为止。然后返回上一级节点,继续遍历其右子节点。
以下是同一个二叉树的深度优先遍历示例:
1
/ \
2 3
/ \ \
4 5 6
深度优先遍历的顺序为:1, 2, 4, 5, 3, 6。遍历过程如下:
- 访问根节点1。
- 遍历左子节点2,访问节点2。
- 遍历左子节点4,访问节点4。
- 返回上一级节点2,遍历右子节点5,访问节点5。
- 返回上一级节点1,遍历右子节点3,访问节点3。
- 遍历右子节点6,访问节点6。
深度优先遍历有三种不同的方式:先序遍历、中序遍历和后序遍历。先序遍历指先遍历访问根节点,然后遍历左子树,最后遍历右子树;中序遍历指先遍历左子树,然后访问根节点,最后遍历右子树;后序遍历指先遍历左子树,然后遍历右子树,最后访问根节点。
下面我们分别来看一下这三种深度优先遍历的实现。
先序遍历
先序遍历的遍历顺序是:根节点 -> 左子树 -> 右子树。
以下是先序遍历的递归实现:
def pre_order_traversal(root):
if root:
print(root.val)
pre_order_traversal(root.left)
pre_order_traversal(root.right)
以下是先序遍历的迭代实现:
def pre_order_traversal(root):
stack = [root]
while stack:
node = stack.pop()
if node:
print(node.val)
stack.append(node.right)
stack.append(node.left)
中序遍历
中序遍历的遍历顺序是:左子树 -> 根节点 -> 右子树。
以下是中序遍历的递归实现:
def in_order_traversal(root):
if root:
in_order_traversal(root.left)
print(root.val)
in_order_traversal(root.right)
以下是中序遍历的迭代实现:
def in_order_traversal(root):
stack = []
node = root
while node or stack:
while node:
stack.append(node)
node = node.left
node = stack.pop()
print(node.val)
node = node.right
后序遍历
后序遍历的遍历顺序是:左子树 -> 右子树 -> 根节点。
以下是后序遍历的递归实现:
def post_order_traversal(root):
if root:
post_order_traversal(root.left)
post_order_traversal(root.right)
print(root.val)
以下是后序遍历的迭代实现:
def post_order_traversal(root):
stack = [(root, False)]
while stack:
node, visited = stack.pop()
if node:
if visited:
print(node.val)
else:
stack.append((node, True))
stack.append((node.right, False))
stack.append((node.left, False))
怎么样理解了么 有问题评论区交流ha

![【从零开始学习 UVM】3.5、UVM TestBench架构 —— UVM Sequencer [uvm_sequencer]](https://img-blog.csdnimg.cn/195f597a6bbf4ea78fbacf540fed2476.png)